

运行截图:

相对于以前的版本此次增加自定义关键词
实例代码:
from bs4 import BeautifulSoup
import requests,re,os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
def Get_Url(url):
response = requests.get(url, headers=headers).text
soup = BeautifulSoup(response,'html.parser')
for data in soup.find_all('a',class_='list-title text-md h-2x'):
url_data = data.get('href')
urls = "https://www.vmgirls.com/" + str(url_data)
Down_Image(urls)
print('-----------------------------------------------')
print(urls)
def Down_Image(url):
response = requests.get(url, headers=headers).text
soup = BeautifulSoup(response, 'html.parser')
image_url = soup.find_all('img')
for data in image_url:
image_type = data.get('src').split('.')[-1]
if image_type == 'jpg' or image_type == 'jpeg' or image_type == 'png':
url_data = data.get('src')
# print(url_data)
dir_name = soup.find(class_='post-title h1').string
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# print(dir_name)
image = requests.get("https:" + str(url_data), headers=headers).content
file_name = url_data.split('/')[-1]
# print(file_name)
with open(dir_name + '/' + file_name, 'wb') as f:
f.write(image)
print('正在写入----->' + dir_name + '/' + file_name)
if __name__ == '__main__':
print(' ---------------------------------------------------------------------')
print('| |')
print('| Author:culprit --- iamdd |')
print('| |')
print(' ---------------------------------------------------------------------')
print('支持搜索关键词(例如少女、小姐姐、青春。。。)')
key = input('请输入关键词(默认回车不输入):')
if key == '':
url = "https://www.vmgirls.com/"
else:
url = "https://www.vmgirls.com/?s=" + key
Get_Url(url)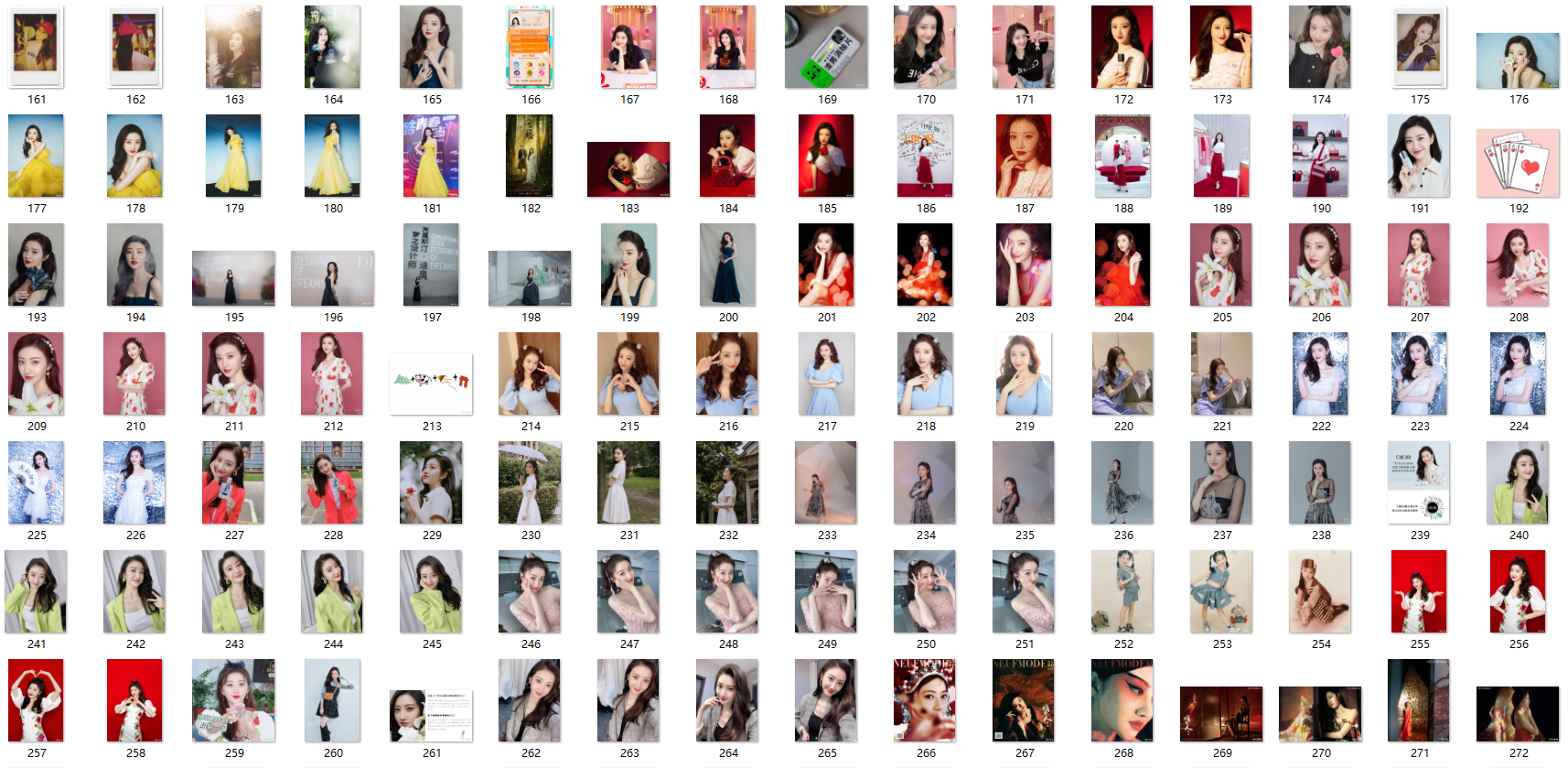

评论 (0)