搜索到
5
篇与
编程技术
的结果
-
 2分钟掌握CSS flexbox布局 和 Grid 布局 flex布局速记 交叉轴横向/* 靠右对齐 */ .a{ justify-content: flex-end; } /* 居中对齐 */ .a{ justify-content: center; } /* 平分空间 */ .a{ justify-content: space-evenly; } /* 两端对齐 */ .a{ justify-content: space-between; }flex布局速记 交叉轴竖向/* 靠下对齐 */ .a{ align-items: flex-end; } /* 居中对齐 */ .a{ align-items: center; }flex布局速记 改变主轴方向/*将主轴方向从默认的横向改为竖向排列*/ .a{ flex-direction: column; } /* flex占比调整 */ .a{ flex: 1; } /*注: 改变主轴方向后原来横向代码将变为竖向,相反竖向代码将变为横向*/
2分钟掌握CSS flexbox布局 和 Grid 布局 flex布局速记 交叉轴横向/* 靠右对齐 */ .a{ justify-content: flex-end; } /* 居中对齐 */ .a{ justify-content: center; } /* 平分空间 */ .a{ justify-content: space-evenly; } /* 两端对齐 */ .a{ justify-content: space-between; }flex布局速记 交叉轴竖向/* 靠下对齐 */ .a{ align-items: flex-end; } /* 居中对齐 */ .a{ align-items: center; }flex布局速记 改变主轴方向/*将主轴方向从默认的横向改为竖向排列*/ .a{ flex-direction: column; } /* flex占比调整 */ .a{ flex: 1; } /*注: 改变主轴方向后原来横向代码将变为竖向,相反竖向代码将变为横向*/ -
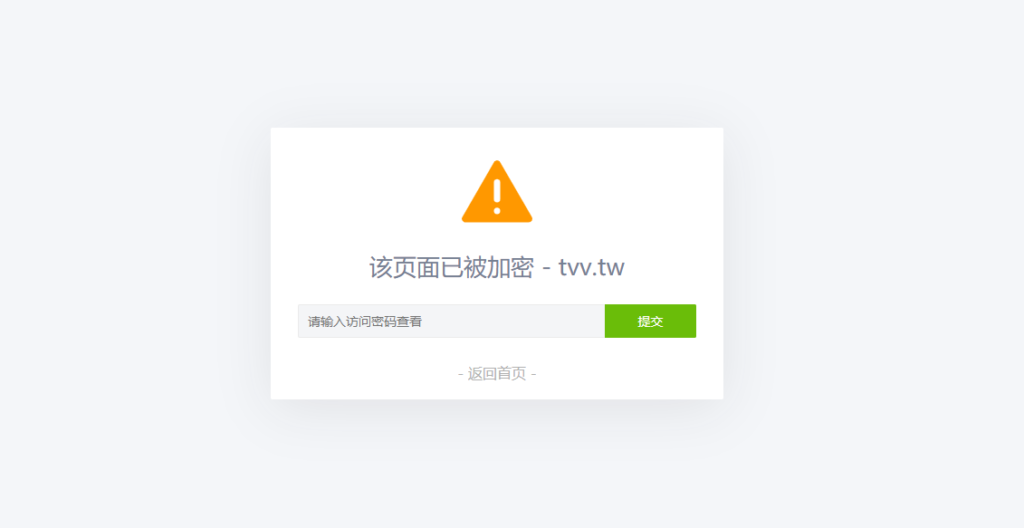
PHP为任意页面设访问密码,需要登录才能访问 使用方法把下面的代码存为php文件,下面的整段代码是验证过程,然后在你入口页进行调用例如命名为MkEncrypt.php,那么在入口页进行require_once('MkEncrypt.php');然后设置密码为MkEncrypt('1234');此时密码为1234则密码正确才能进去页面,进入后会存下cookies值,下一次登录的时候则不需要再次输入了;如果不想给人看了,只需要更改密码,cookies就会立即失效,必须要重新登陆才能看。代码简介为你的页面 支持 加密访问 无论什么程序 只要是PHP程序 都是支持这代码的 来实现加密访问你的加密页面 或文章等等的页面 不保证其他程序可以正常使用 麻烦先测试!代码如下<?php /******************************************** * 使用方法: * * 1、将本段代码保存为 MkEncrypt.php * * 2、在要加密的页面前面引入这个 php 文件 * require_once('MkEncrypt.php'); * * 3、设置页面访问密码 * MkEncrypt('页面密码'); * ********************************************/ // 密码 Cookie 加密盐 if(!defined('MK_ENCRYPT_SALT')) define('MK_ENCRYPT_SALT', 'Kgs$JC!V'); /** * 设置访问密码 * * @param $password 访问密码 * @param $pageid 页面唯一 ID 值,用于区分同一网站的不同加密页面 */ function MkEncrypt($password, $pageid = 'default') { $pageid = md5($pageid); $md5pw = md5(md5($password).MK_ENCRYPT_SALT); $postpwd = isset($_POST['pagepwd']) ? addslashes(trim($_POST['pagepwd'])) : ''; $cookiepwd = isset($_COOKIE['mk_encrypt_'.$pageid]) ? addslashes(trim($_COOKIE['mk_encrypt_'.$pageid])) : ''; if($cookiepwd == $md5pw) return; // Cookie密码验证正确 if($postpwd == $password) { // 提交的密码正确 setcookie('mk_encrypt_' . $pageid, $md5pw, time() + 3600000, '/'); return; } ?> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="renderer" content="webkit"> <meta name="author" content="mengkun"> <meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no"> <title>该页面已被加密</title> <style type="text/css"> *{font-family:"Microsoft Yahei",微软雅黑,"Helvetica Neue",Helvetica,"Hiragino Sans GB","WenQuanYi Micro Hei",sans-serif;box-sizing:border-box;margin:0px;padding:0px;font-size:14px;-webkit-transition:.2s;-moz-transition:.2s;-ms-transition:.2s;-o-transition:.2s;transition:.2s} html,body{width:100%;height:100%} body{background-color:#F4F6F9;color:#768093} input,button{font-size:1em;border-radius:3px;-webkit-appearance:none} input{width:100%;padding:5px;box-sizing:border-box;border:1px solid #e5e9ef;background-color:#f4f5f7;resize:vertical} input:focus{background-color:#fff;outline:none} button{border:0;background:#6abd09;color:#fff;cursor:pointer;opacity:1;user-select:none} button:hover,button:focus{opacity:.9} button:active{opacity:1} .main{width:100%;max-width:500px;height:300px;padding:30px;background-color:#fff;border-radius:2px;box-shadow:0 10px 60px 0 rgba(29,29,31,0.09);transition:all .12s ease-out;position:absolute;left:0;top:0;bottom:0;right:0;margin:auto;text-align:center} .alert{width:80px} .mk-side-form{margin-bottom:28px} .mk-side-form input{float:left;padding:2px 10px;width:77%;height:37px;border:1px solid #ebebeb;border-right-color:transparent;border-radius:2px 0 0 2px;line-height:37px} .mk-side-form button{position:relative;overflow:visible;width:23%;height:37px;border-radius:0 2px 2px 0;text-transform:uppercase} .pw-tip{font-weight:normal;font-size:26px;text-align:center;margin:25px auto} #pw-error {color: red;margin-top: 15px;margin-bottom: -20px;} .return-home{text-decoration:none;color:#b1b1b1;font-size:16px} .return-home:hover{color:#1E9FFF;letter-spacing:5px} </style> </head> <body> <div class="main"> <svg class="alert" viewBox="0 0 1084 1024" xmlns="http://www.w3.org/2000/svg" width="80" height="80"> <defs><style/></defs> <path d="M1060.744 895.036L590.547 80.656a55.959 55.959 0 0 0-96.919 0L22.588 896.662a55.959 55.959 0 0 0 48.43 83.907h942.14a55.959 55.959 0 0 0 47.525-85.534zm-470.619-85.172a48.008 48.008 0 1 1-96.015 0v-1.567a48.008 48.008 0 1 1 96.015 0v1.567zm0-175.345a48.008 48.008 0 1 1-96.015 0V379.362a48.008 48.008 0 1 1 96.015 0v255.157z" fill="#FF9800"/> </svg> <form action="" method="post" class="mk-side-form"> <h2 class="pw-tip">该页面已被加密</h2> <input type="password" name="pagepwd" placeholder="请输入访问密码查看" required><button type="submit">提交</button> <?php if($postpwd): ?> <p id="pw-error">Oops!密码不对哦~</p> <script>setTimeout(function() {document.getElementById("pw-error").style.display = "none"}, 2000);</script> <?php endif; ?> </form> <a href="/" class="return-home" title="点击回到网站首页">- 返回首页 - </a> </div> </body> </html> <?php exit(); }文件下载如果还是不会就直接下载这个加密文件 然后上传到你的服务器调用{cloud title="点击下载" type="lz" url="https://suua.lanzoui.com/iu8b3nbrj8d" password=""/}在要加密的页面前面引入这个 php 文件require_once('MkEncrypt.php'); //引入加密文件,如果这个引入无效可以使用:include("MkEncrypt.php"); 来引入(注意文件目录正确) MkEncrypt('123456'); //访问当前页面的密码(这里密码为123456 自行修改即可)
-
-
支付宝当面付(PHP Demo)小白教程 1.先找到蚂蚁金服开发平台下载Demo(地址:https://docs.open.alipay.com/194/105201/)2.用支付宝工具去生成一个公钥和私钥(工具地址:https://docs.open.alipay.com/291/105971/)3.把下载下来的Demo解压后打开config.php文件把生成的私钥跟支付宝给你的支付宝公钥填写上。注意的是私钥生成的时候要把私钥保存好。(文件位置:dangmianfu_demo_php/f2fpay/config)3.1)这里是查看自己的APP_ID和支付公钥(地址:https://openhome.alipay.com/platform/keyManage.htm)4.现在开打f2fpay/qrpay_test.php文件这里可以把一些不需要的参数可以去掉(把必填的参数留住就行)4.1)填写完成后接下来就可以测试一下了,下面是访问我的本地测试地址(localhost/ailpay/dangmianfu_demo_php/f2fpay/qrpay_test.php)4.2)点击确定后如果成功了就会返回二维码地址给你注意:如果失败不返回就去检查一下你的公钥和私钥APP_ID是否正确4.3)返回的二维码地址是访问不到二维码的。需要用工具生成。这里我使用的是phpqrcode (下载地址:https://sourceforge.net/projects/phpqrcode/)下载下来以后把phpqrcode.php文件拖到你的项目目录里面。在f2fpay/qrpay_test.php文件里面加载工具文件进来。4.4)点击确定后如果成功了就会返回支付宝二维码给你看看扫出的钱是否与你填写的金额相同就行。5.回调方法5.1)自己写一个回调方法然后在config.php配置文件里面填写好。5.2)还需要在 f2fpay/service/AlipayTradeService.php文件中添加回调信息。5.3)回调方法用于如果支付成功就会给返回订单号。根据订单号更改订单状态即可。6.接下来就是需要把logo加入到二维码中间和把图片保存到本地的。6.1)在f2fpay/qrpay_test.php文件中生成二维码成功的时候来对图片处理,首先准备好需要放到二维码中间的logo图片存放到项目的某个目录下。蚂蚁技术支持中心-故障排查云排查
-
python打包成exe可执行文件教程 本文,介绍一下把python代码打包成windows的可执行文件的方法。步骤1安装pywin32,可以参考《怎么给python安装pywin32模块?》一定要注意对应的python版本,否则不能安装。步骤2用命令行调用pip安装pyinstaller。步骤3准备一个py文件。我这里准备的是一个爬取电子书的python文件——00.py。步骤4准备一个图片,作为exe的图标:b.ico注意图片格式是ico的,大小为32*32,不要太大。没有的话,可以在网上免费转格式。把00.py和b.ico放到一个目录里面——C:\a步骤5把cmd的当前目录切换到C:\a。步骤6然后执行命令行:pyinstaller -F -i b.ico 00.py注意:文件名后面不要有后缀,直接00和b步骤7运行之后,cmd变成了这样。步骤8在C:\a目录里面,多出了几个文件夹。可执行文件00.exe就在dist文件夹里面。步骤9双击可执行文件,会弹出一个命令提示符端口,提示你输入书号。按照格式输入书号,点击回车键,就可以在dist文件夹里面,看到一章章的电子书被下载下来了。exe的图标,一定要是ico格式。